
知识图谱相关技术
知识图谱相关技术
概览
知识图谱是一个综合性非常强的知识体系,对应到项目上,知识图谱涉及到范围很广,需要多方面的人才和技术,包括上游的业务理解和图谱设计,再包括中间构建过程中,从文本到知识再到采用NLP技术对知识进行一些处理,再到下游的应用,诸如问答、推荐等应用。

业务理解
对于业务的理解,占整个知识图谱重要性要达50%,相对技术来说,反而业务理解是更重要的。
知识图谱建完后干什么?->为什么要建知识图谱?
对业务的理解:
- 有哪些可获取的业务数据?
- 我所需的业务数据有没有对应的一些开源网站,这些开源网站数据结构化程度如何?是否容易获取?或者有没有自有资源?
- 如果需要获取数据以及人工标注,需要多大成本?
- 有些数据是可以获取,但是数据结构化程度不高,采用人工标注成本是多大?对比有了知识图谱对业务性能的提升,效益是否超过了成本?
- 是否需要专家介入?
- 有些领域的知识图谱是短时间内可以学会的,但有些领域比如医疗领域某些科目就需要专家支援。
- 业务数据的特性是什么样的?
- 我们的业务数据是否简单点与点联系(不需要知识图谱,一般数据库表示即可)?有无网状联系?
- 业务数据是否用一般数据库表示即可?
- 通过这些关系表示,能否给场景带来实际益数处?
- 有些数据可能是有网状关系,但是任务对应的具体业务没用到网状关系,所以我们不需要做知识图谱。
- 在熟悉业务的场景下,构建边界清晰、产出可用的知识图谱。
案例

对于刑期预测,其实没必要去做一个知识图谱,因为刑期可能就是跟文本中一系列属性相关,比如罪犯对应的行为和对应个人的经历,与各个罪犯之间没有特别大的关联,所以知识图谱对罪犯刑期预测没有太大的作用。这个任务更多的是对当事人对应的案情描述的文本进行具体分析、特征提取再去预测刑期。
对于妇科相关的问答系统搭建案例,对于这个场景,是有很多实体的,比如药物对应的症状、病人的状态、治疗手段、生活习惯都可以作为实体,且这些实体之间都有联系。比如病人状态是否有过生育史对推荐的药物是有影响的。再比如病人在不同的疗程阶段,表现和症状都是不同的,在这种情况下,是有实体和相应的关联。可以辅助问答系统去更加精确的回答问题。
图谱设计
在业务理解后确定要做知识图谱,接下来的就是图谱设计的阶段。知识图谱的元素有顶点和边两个基础元素,图谱的设计就是去定义、去约束、去组织这些元素的表现形式。所以,在真实的领域场景中如何抽象实体和关系,这些实体和关系又有怎样的属性,是我们在设计图谱期间需要确定的。
现实场景中的哪些事物可抽象为实体? —> 构建知识图谱的基础
各类实体分别具有哪些属性? —> 限定了数据范围
实体间存在什么关系?关系有什么属性? —> 约束了数据的操作范围
总的来看,不同的图谱设计,不同的业务逻辑,不同的下游应用。
案例1
下面是两个人对同样的数据做出的不同的两份图谱设计,可以明显从表现形式看出两者的不同。从第一个图谱,我们仅能发现妖怪、道、佛间的关系,但从第二个知识图谱可视化中,我们可以得出与道、佛相关的妖怪最终被打死的很少。不同设计的图谱表达出的含义及侧重点有所不同。
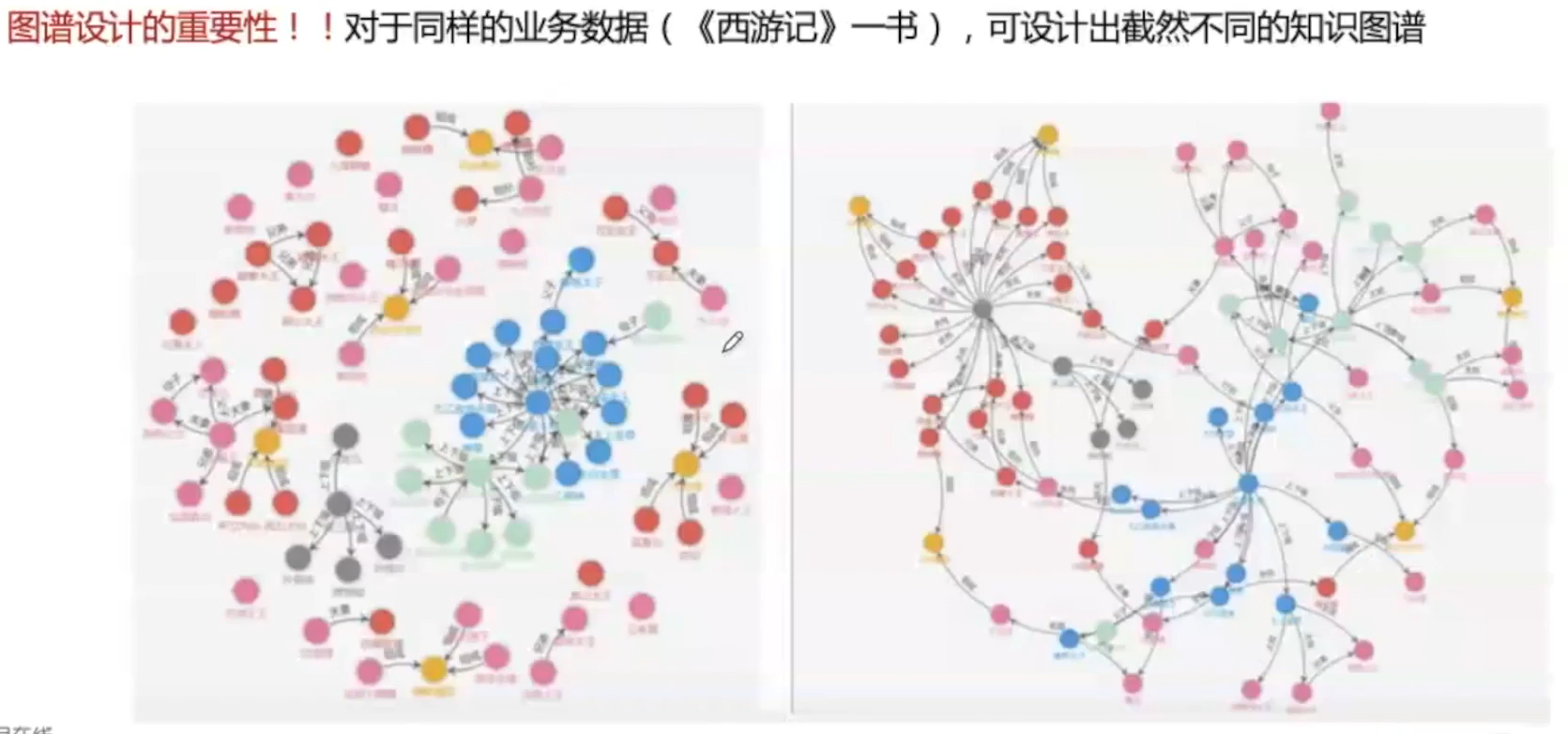
实体
- 粉色:妖怪
- 红色:最后死掉的妖怪
- 黄色:妖怪联盟
- 蓝色:道
- 绿色:佛
- 灰色:取经团队
关系
左边图谱定义的关系有:
- 血缘
- 结盟
- 上下级
右边图谱定义的关系有:
- 制裁
- 隐性关系
案例2*
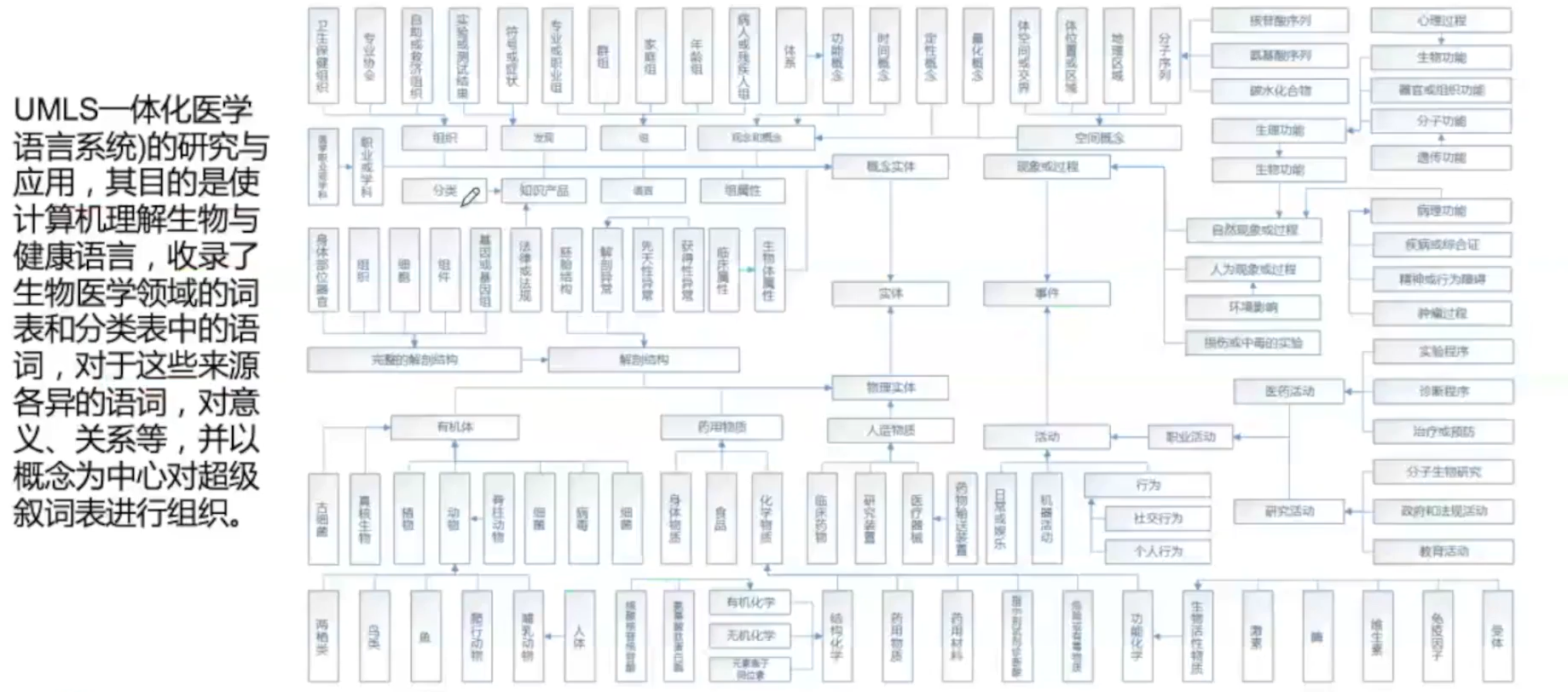
我们在图谱设计的时候要抽象一些关系,此时我们就需要了解有哪些相关关系,但具体有哪些,如果光靠我们自己猜想,是很不规范的。此时,我们可以参考下面这张表进行分析:
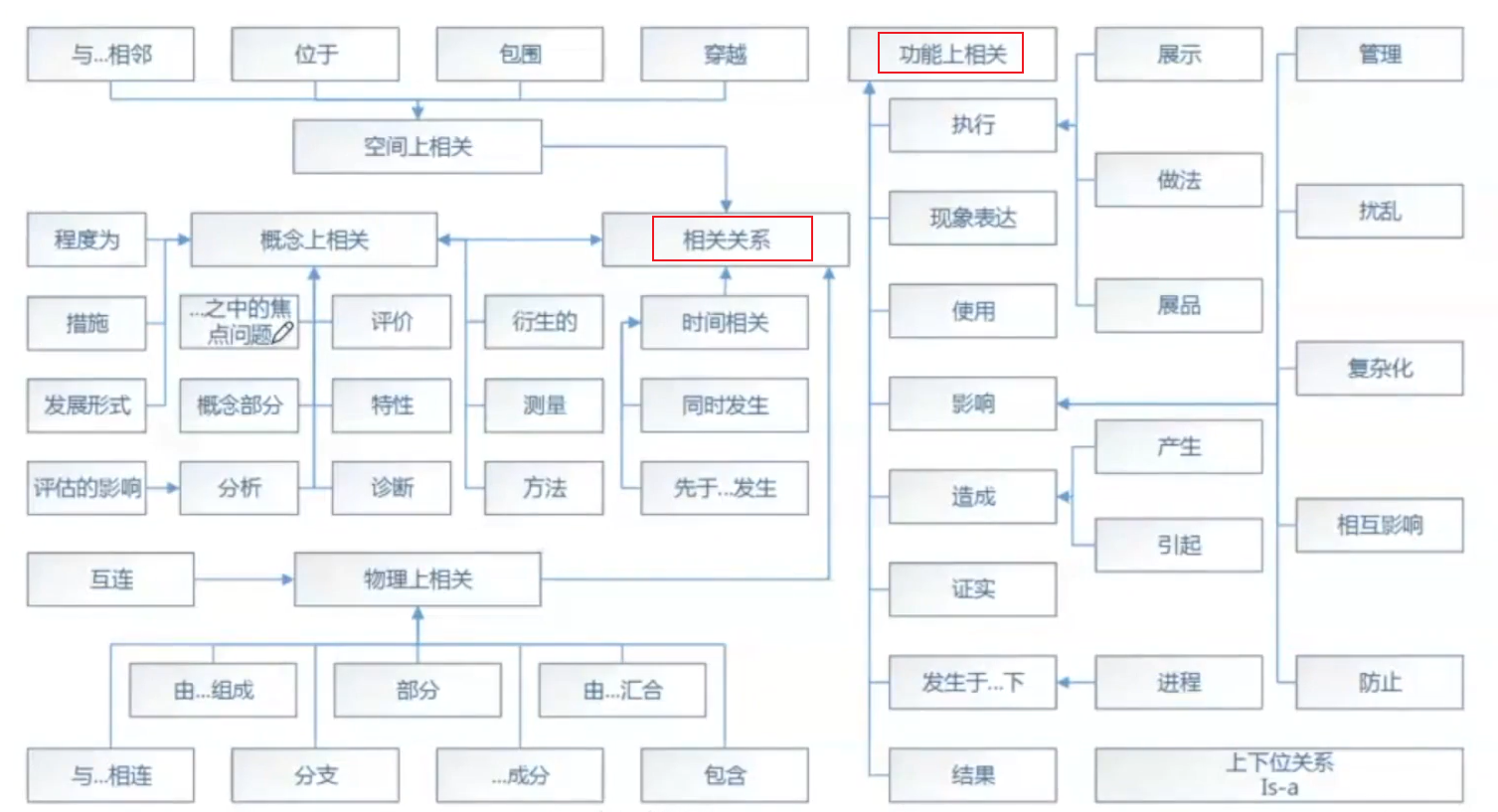
根据上面这张表,我们就知道了规范化的关系类型,再结合关系类型从业务出发,再去抽象出对应的业务数据对应的关系。
比如,我们以“中药”为起点来构建关系,我们可以参照上面的关系表,再对照业务数据构建一些相关关系。
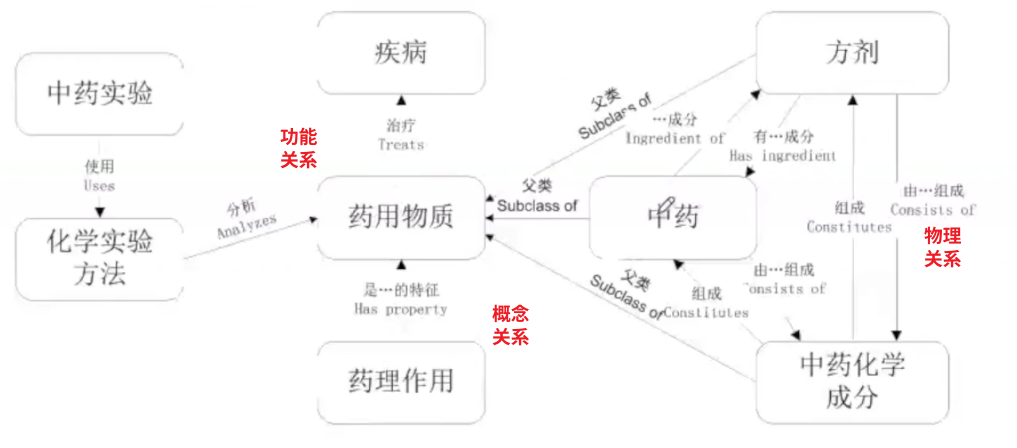
总结
基于业务设计图谱,基于可用人员选择方法。
- 专家法:自上而下,总体规划;领域专家(技术+业务)
- 归纳法:单点切入,自下而上(针对一个单点的业务场景纵向打破,然后再基于这一套模式横向扩展);技术专家
- 混合法:一味用专家法,细节不足,一味用归纳法,高度不够,可以综合两者,比如大的方向上用专家法,小的场景下用归纳法
- 参照法:标杆对照,适配调整;行业标准
关于图谱设计经验:
- 业务理解和相应的技术要并行;
- 不断迭代修整知识图谱(图谱设计的迭代、内容的迭代);
- 小规模实践;(小部分数据测试)
- 定时可视化知识图谱全貌(直观感受);
- 验证图谱对应用工程的有效性;
知识抽取

知识表示
知识图谱是由一条条知识组成,每条知识表示为一个SPO三元组(Subject-Predicate-Object)。
在知识图谱中,我们用RDF形式化地表示这种三元关系。
资源描述框架(Resource Description Framework,RDF)是一个使用XML语法来表示的资料模型(Datamodel),用来描述Web资源的特性,及资源与资源之间的关系。

概念解释
资源(Resource):所有以RDF表示法来描述的东西都叫做资源,它可能是一个网站,可能是一个网页,可能只是网页中的某个部分,甚至是不存在于网络的东西,如纸本文献、器物、人等,都以统一资源标识(URl,Uniform Resource Indentifiers)来命名。
属性(Properties):用来描述资源的特定特征或关系。
陈述(Statements):一个RDF陈述,其中资源是主词(Subject),属性是述词(Predicate),属性值则是受词(Object),这是一种描述语法。
RDF图中一共有三种类型,International Resource Identifiers(IRIs)(与前面我们介绍的URI是同一个东西,区别在于URI只能用英文字符,IRI是国际化资源通用的标识符),blank nodes(空)和literals(字符串)。下面是SPO每个部分的类型约束:
- Subject可以是IRI或blank node。
- Predicate是IRI。
- Object三种类型都可以。
RDF数据存储传输
目前,RDF序列化的方式主要有:RDF/XML,N-Triples,Turtle,RDFa,JSON-LD等几种。
- N-Triples(在N-Triples格式下RDF三元组的表现形式):
<http://www.kg.com/person/1>[IRI:Subject]<www.kg.com/RepresentativeWork>[IRI:Predicate]"底特律的流产"^^string[literals:Object]
- Turtle(相较N-Triples,采用简化符号表达三元组):
- @prefix person:
<http://www.kg.com/person/1> - @prefix:
<http://www.kg.com/> - person:1: RepresentativeWork”底特律的流产”^^string
- @prefix person:
RDF表示方式缺陷
<http://www.kg.com/person/1><www.kg.com/RepresentativeWork>"底特律的流产"^^xsd:string
以上这种简单的表达方式存在以下缺陷:
- 有些知识和时空相关,也具有不确定性。
- 奥巴马,就职,美国总统(是很久之前的事情,与时间相关,这样表示信息不完全)
- 番茄,有助于,补铁(不是一个定论,是有一定概率的,所以应该要加上一个概率性)
- 因此,我们应该给三元组加上一个跟时间、概率相关的属性,表示成:(s, p, o) : a
- RDF表达能力有限,无法区分类和对象,也无法定义和描述类的关系或属性。
- 简单来说RDF对于具体事务的描述缺乏抽象的能力。
- 无法抽象通性知识。
因此就出现了RDFS和OWL这两种模式语言。
RDFS和OWL这两种技术或者说模式语言/本体语言schema/ontology language)解决了RDF表达能力有限的困境。
RDFS即RDF Schema,在RDF的基础上预定义了一些规则。
介绍RDFS几个比较重要,常用的概念:
- rdfs:Class.用于定义类。
- rdfs:dorain.用于表示该属性属于哪个类别。
- rdfs:range.用于描述该属性的取值类型。
- rdfs:subClassOf.用于描述该类的父类。
- 5rdfs:subProperty.用于描述该属性的父属性。
知识存储

知识图谱|知识存储
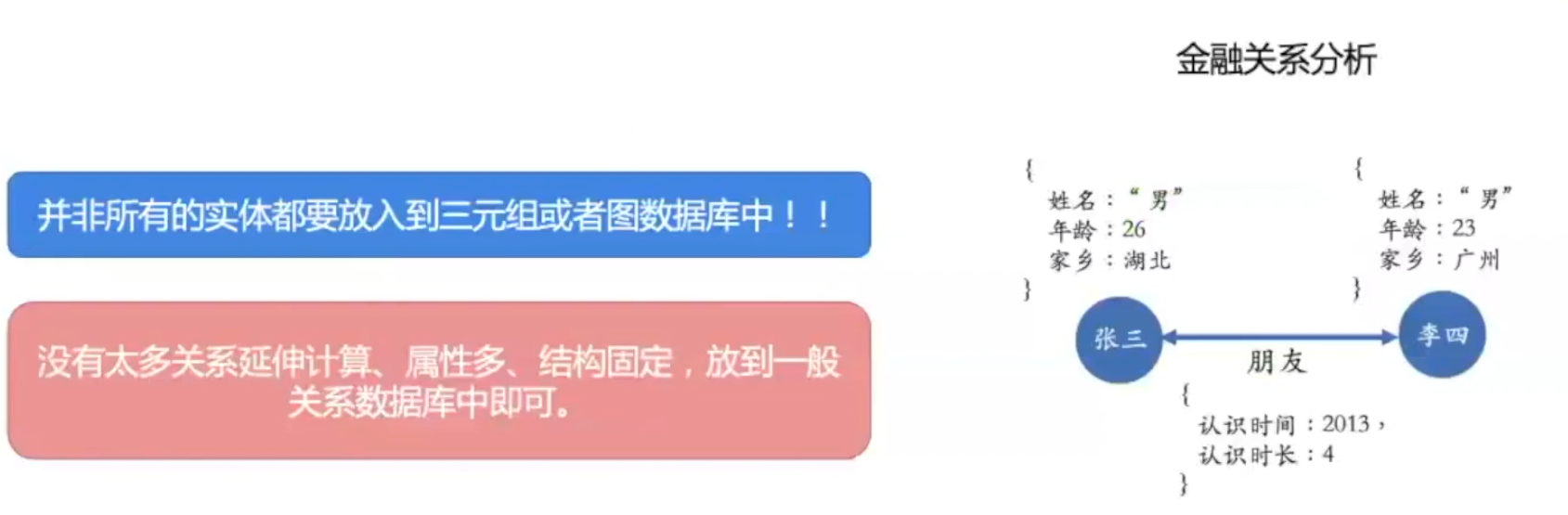
对于上图金融关系分析中,我们可以把年龄、家乡信息存放到传统的关系型数据库中,原因有两点:
- 这些数据对于分析关系来说没有太多作用;
- 访问频率低,放在知识图谱上反而影响效率;
所以,我们在存储知识图谱数据时,都是多种数据库并行的。
知识链接
知识链接是发生在我们构建好知识图谱后,想从文本中引入更多知识的时候。

如何将对同一个实体不同称呼的知识扩充到KG需要用到知识链接的技术。
对于一实体存在对应的两个不同实体,在做文本分析时用知识链接手段,结合更多信息,前后文信息去确认实体实际指的实体或者根据文章领域或者实体知名度来判断。
知识融合
在两个数据库中,有对应的两个实体(实际上对应同一个实体),是两个知识,这两个知识在两个数据库中表现形式不一样,我们需要把这两个实体进行融合。
比如我们分别针对豆瓣和百度百科构建了两个知识图谱,现在想将这两个知识图谱融合,如何保证两个知识图谱上的实际上是相同的两个实体信息能够融合在一起?
这种需要针对两个实体对应的属性或关系做一个相似度匹配,如果匹配度高,说明这两个人可能是同一个人。






