基于NFM和GRU模型的流行度预测模型 差不多有半个月没更新了,最近事情有点多,整了个小程序,帮一个师兄搭了一个流行度预测二分类神经网络模型。本篇文章就简单介绍下这个模型,记录下花费的时间。
数据背景 首先呢,到手数据不到一万多条,二分类因变量比例大于3:7,数据字段如下:
视频or文本内容ID
文本+作者本身特征(文本字符数、专业性词汇数、指令性词汇数、粉丝数、粉丝价值RFM等)
时间序列特征(day1点赞、day_1评论、day1 分享……day15_xxx)
流行度标签(根据内容用户参与度计算)
xxxxxxx
xxxxxxx
xxxxxxx
xxxxxxx
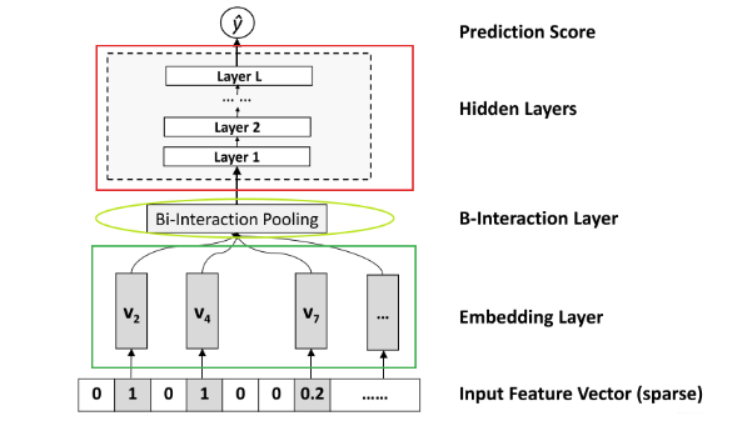
NFM模型 NFM模型,NFM,简称神经分解机。是FM模型的一个进阶版本。该模型主要解决了FM模型以线性的方式学习二阶特征交互,导致捕获现实数据非线性和复杂的内在结构表达力不够的问题。其主要创新点在于深度网络和嵌入层对嵌入向量二阶特征的组合建模。
NFM(Neural Factorization Machines)是2017年由新加坡国立大学的何向南教授等人在SIGIR会议上提出的一个模型,作者首先分析了一下FM存在的问题,没法考虑高阶特征交互的问题, 这个在模拟复杂内在结构和规律性的真实数据时,FM的能力会受到限制,所以DeepFM的作者才想到了用FM和DNN网络进行一种并联的方式, 两者接收同样的输入, 但是各自学习不同的特征(一个负责低阶交互,一个负责高阶交互), 最后再把学习到的结果合并得到最终的输出,并通过实验也证明了这种策略的有效性。
Embedding Layer 和其他的DNN模型处理稀疏输入一样,Embedding将输入转换到低维度的稠密的嵌入空间中进行处理。这里做稍微不同的处理是,使用原始的特征值乘以Embedding vector,使得模型也可以处理real valued feature 。
Bi-Interaction Layer Bi是Bi-linear的缩写,这一层其实是一个pooling层操作,它把很多个向量转换成一个向量。
有个问题是 这里直接使用特征向量 的element-wise product后累加,会有比较大的信息损失,而好处是也减少了参数。
Hidden Layer 这个跟其他的模型基本一样,堆积隐藏层以期来学习高阶组合特征。
Prediction Layer 这种对FM的新观点具有一定的启发性 , 可以为改进FM提供更多见解,我们允许在FM上使用各种神经网络技术来提高其学习和泛化能力, 比如可以采用常用的dropout方法来避免过拟合——用在Bi-Interaction层上, 就相当于添加了FM的正则, 这种方式甚至比常规的l2正则更有效果。
参考:
推荐系统遇上深度学习(七)—NFM模型理论和实践 - 云+社区 - 腾讯云 (tencent.com)
NFM模型分析—-FM与DNN相结合,附TF2.x复现 - 知乎 (zhihu.com)
基于Pytorch实现NFM模型 NFM模型主要用于处理大量稀疏的文本+作者本身相关特征。不得不说,有工具是真的能节省很大一部分时间。
导入包: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 """导入包""" import numpy as npimport pandas as pdimport matplotlib.pyplot as pltfrom tqdm import tqdmimport datetimeimport torchfrom torch.utils.data import DataLoader, Dataset, TensorDatasetimport torch.nn as nnimport torch.nn.functional as Fimport torch.optim as optimfrom torchkeras import summary, Modelfrom sklearn.metrics import roc_auc_scorefrom sklearn.metrics import classification_reportfrom sklearn.metrics import f1_scorefrom sklearn.metrics import precision_score,confusion_matriximport warningswarnings.filterwarnings('ignore' ) from IPython.core.interactiveshell import InteractiveShellInteractiveShell.ast_node_interactivity = "all"
创建工具函数: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 def clear_output (): """ clear output for both jupyter notebook and the console """ import os os.system('cls' if os.name == 'nt' else 'clear' ) if is_in_notebook(): from IPython.display import clear_output as clear clear() def is_in_notebook (): import sys return 'ipykernel' in sys.modules
准备数据: NFM模型需要对稀疏的类别特征做一个embeding。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 def prepared_data (dict_data ): if dict_data['set_val_set' ]: train = pd.read_csv(dict_data['trn_file_path' ]) val = pd.read_csv(dict_data['val_file_path' ]) test = pd.read_csv(dict_data['test_file_path' ]) val_x, val_y = val.drop(columns=['' , '' ]).values, val['' ].values else : train = pd.read_csv(dict_data['trn_file_path' ]) test = pd.read_csv(dict_data['test_file_path' ]) trn_x, trn_y = train.drop(columns=['' , '' ]).values, train['' ].values test_x, test_y = test.drop(columns=['' , '' ]).values, test['' ].values fea_col = np.load(dict_data['npy_path' ], allow_pickle=True ) print (fea_col) return fea_col, (trn_x, trn_y), (test_x, test_y) """导入数据""" fea_col, (trn_x, trn_y), (test_x, test_y) = prepared_data(dict_data) dl_train_dataset = TensorDataset(torch.tensor(trn_x).float (), torch.tensor(trn_y).float ()) dl_val_dataset = TensorDataset(torch.tensor(test_x).float (), torch.tensor(test_y).float ()) dl_train = DataLoader(dl_train_dataset, shuffle=True , batch_size=128 ) dl_val = DataLoader(dl_val_dataset, shuffle=True , batch_size=128 )
构建NFM模型: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 class Dnn (nn.Module): def __init__ (self, hidden_units, dropout=0. ): """ hidden_units: 列表, 每个元素表示每一层的神经单元个数, 比如[256, 128, 64], 两层网络, 第一层神经单元128, 第二层64, 第一个维度是输入维度 dropout = 0. """ super (Dnn, self).__init__() """ nn.ModuleList: 将submodules保存在一个list中。 ModuleList可以像一般的Python list一样被索引。 而且ModuleList中包含的modules已经被正确的注册,对所有的module method可见。 nn.Linear 对输入数据做线性变换:y = ax + b in_features - 每个输入样本的大小 out_features - 每个输出样本的大小 bias - 若设置为False,这层不会学习偏置。默认值:True zip(hidden_units[:-1], hidden_units[1:]): 对接前后层的输出输入网络 nn.Dropout 随机将输入张量中部分元素设置为0。对于每次前向调用,被置0的元素都是随机的。 p - 将元素置0的概率。默认值:0.5 in-place - 若设置为True,会在原地执行操作。默认值:False """ self.dnn_network = nn.ModuleList([nn.Linear(layer[0 ], layer[1 ]) for layer in list (zip (hidden_units[:-1 ], hidden_units[1 :]))]) self.dropout = nn.Dropout(dropout) def forward (self, x ): for linear in self.dnn_network: x = linear(x) """ 非线性激活函数relu 好处: ReLu具有稀疏性,可以使稀疏后的模型能够更好地挖掘相关特征,拟合训练数据 在x>0区域上,不会出现梯度饱和、梯度消失的问题 计算复杂度低,不需要进行指数运算,只要一个阈值就可以得到激活值 缺点: 由于小于0的时候激活函数值为0,梯度为0,所以存在一部分神经元永远不会得到更新 """ x = F.relu(x) x = self.dropout(x) return x class NFM (nn.Module): def __init__ (self, feature_columns, hidden_units, dnn_dropout=0. ): """ NFM: :param feature_columns: 特征信息, 这个传入的是fea_cols :param hidden_units: 隐藏单元个数, 一个列表的形式, 列表的长度代表层数, 每个元素代表每一层神经元个数 """ super (NFM, self).__init__() self.dense_feature_cols, self.sparse_feature_cols = feature_columns self.embed_layers = nn.ModuleDict({ 'embed_' + str (i): nn.Embedding(num_embeddings=feat['feat_num' ], embedding_dim=feat['embed_dim' ]) for i, feat in enumerate (self.sparse_feature_cols) }) """ 这里要注意Pytorch的linear和tf的dense的不同之处, 前者的linear需要输入特征和输出特征维度, 而传入的hidden_units的第一个是第一层隐藏的神经单元个数, 这里需要加个输入维度 """ self.fea_num = len (self.dense_feature_cols) + self.sparse_feature_cols[0 ]['embed_dim' ] hidden_units.insert(0 , self.fea_num) """ nn.BatchNorm1d 对小批量(mini-batch)的2d或3d输入进行批标准化(Batch Normalization)操作 在每一个小批量(mini-batch)数据中,计算输入各个维度的均值和标准差。 gamma与beta是可学习的大小为C的参数向量(C为输入大小) 在训练时,该层计算每次输入的均值与方差,并进行移动平均。移动平均默认的动量值为0.1。 在验证时,训练求得的均值/方差将用于标准化验证数据。 num_features: 来自期望输入的特征数 """ self.bn = nn.BatchNorm1d(self.fea_num) self.dnn_network = Dnn(hidden_units, dnn_dropout) self.nn_final_linear = nn.Linear(hidden_units[-1 ], 2 ) def forward (self, x ): dense_inputs, sparse_inputs = x[:, :len (self.dense_feature_cols)], x[:, len (self.dense_feature_cols):] sparse_inputs = sparse_inputs.long() sparse_embeds = [self.embed_layers['embed_' +str (i)](sparse_inputs[:, i]) for i in range (sparse_inputs.shape[1 ])] """ torch.stack 沿着一个新维度对输入张量序列进行连接。 序列中所有的张量都应该为相同形状。 sqequence (Sequence) – 待连接的张量序列 dim (int) – 插入的维度。必须介于 0 与 待连接的张量序列数之间。 """ sparse_embeds = torch.stack(sparse_embeds) sparse_embeds = sparse_embeds.permute((1 , 0 , 2 )) embed_cross = 1 /2 * ( torch.pow (torch.sum (sparse_embeds, dim=1 ),2 ) - torch.sum (torch.pow (sparse_embeds, 2 ), dim=1 ) ) x = torch.cat([embed_cross, dense_inputs], dim=-1 ) x = self.bn(x) dnn_outputs = self.nn_final_linear(self.dnn_network(x)) outputs = dnn_outputs return outputs
初始化模型的参数: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 hidden_units = [128 , 64 , 32 ] dnn_dropout = 0.5 model = NFM(fea_col, hidden_units, dnn_dropout) summary(model, input_shape=(trn_x.shape[1 ],)) """ nn.BCELoss 计算 target 与 output 之间的二进制交叉熵 nn.CrossEntropyLoss 注意,使用nn.CrossEntropyLoss()时,由于其自带softmax,不需要现将输出经过softmax层,否则计算的损失会有误,即直接将网络输出用来计算损失即可 https://blog.csdn.net/weixin_38314865/article/details/104311969 https://zhuanlan.zhihu.com/p/98785902 nn.NLLLoss() 把输出张量与Label对应的索引下标的张量拿出来,再去掉负号,再求均值。 """ loss_func = nn.CrossEntropyLoss() """ params (iterable) – 待优化参数的iterable或者是定义了参数组的dict lr (float, 可选) – 学习率(默认:1e-3) l2正则化: weight_decay=0.001 ... """ optimizer = optim.Adam(params=model.parameters(), lr=0.0006 ) metric_func = metric_func metric_name = 'acc'
模型训练: 这里分了epoch个回合,每个回合跑多批数据,数据批次=输入数据维度(x方向)/batch_size。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 clear_output() epochs = 150 log_step_freq = 150 dfhistory = pd.DataFrame(columns=['epoch' , 'loss' , metric_name, 'val_loss' , 'val_' +metric_name]) print ('start_training.........' )nowtime = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S' ) print ('========' *8 + '%s' %nowtime)for epoch in range (1 , epochs+1 ): model.train() loss_sum = 0.0 metric_sum = 0.0 step = 1 for step, (features, labels) in enumerate (dl_train, 1 ): optimizer.zero_grad() predictions = model(features); loss = loss_func(predictions, labels.to(torch.long)) try : metric = metric_func("acc" , F.softmax(predictions), labels) except ValueError: pass loss.backward() optimizer.step() loss_sum += loss.item() metric_sum += metric.item() if step % log_step_freq == 0 : print (("[step=%d] loss: %.3f, " + metric_name + ": %.3f" ) % (step, loss_sum/step, metric_sum/step)); model.eval () val_loss_sum = 0.0 val_metric_sum = 0.0 val_step = 1 for val_step, (features, labels) in enumerate (dl_val, 1 ): with torch.no_grad(): predictions = model(features) predictions = predictions.squeeze(1 ) val_loss = loss_func(predictions, labels.to(torch.long)) try : val_metric = metric_func("acc" , F.softmax(predictions), labels) except ValueError: pass val_loss_sum += val_loss.item() val_metric_sum += val_metric.item() info = (epoch, loss_sum/step, metric_sum/step, val_loss_sum/val_step, val_metric_sum/val_step) dfhistory.loc[epoch-1 ] = info print (("\nEPOCH=%d, loss=%.3f, " + metric_name + " = %.3f, val_loss=%.3f, " + "val_" + metric_name + " = %.3f" ) %info) nowtime = datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S" ) print ('\n' + '==========' * 8 + '%s' %nowtime) print ('Finished Training' )
检验模型效果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 def plot_metric (dfhistory, metric ): train_metrics = dfhistory[metric] val_metrics = dfhistory['val_' +metric] epochs = range (1 , len (train_metrics) + 1 ) plt.plot(epochs, train_metrics, 'bo--' ) plt.plot(epochs, val_metrics, 'ro-' ) plt.title('Training and validation ' + metric) plt.xlabel("Epochs" ) plt.ylabel(metric) plt.legend(["train_" +metric, 'val_' +metric]) plt.show() plot_metric(dfhistory,"loss" ) plot_metric(dfhistory,"acc" )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 def res_metrics (model, x, y_true, target_labels ): y_pred_probs = model(torch.tensor(x).float ()) y_pred_probs = F.softmax(y_pred_probs) y_pred = y_pred_probs.argmax(dim=1 ).numpy() target_names = ['class 0' , 'class 1' ] print (classification_report(y_true, y_pred, target_names=target_labels)) print (precision_score(y_true, y_pred, average='micro' )) target_labels = ['class 0' , 'class 1' ] res_metrics(model, test_x, test_y, target_labels)
模型保存加载: 这里需要注意,要加载训练好的模型,需要将对应模型的类给构建好后,才能导入模型,否则会报错找不到模型,无法加载,这应该是Pytorch的一个bug吧。
1 2 torch.save(model, './NFM.pkl' ) nfm = torch.load('./NFM.pkl' )
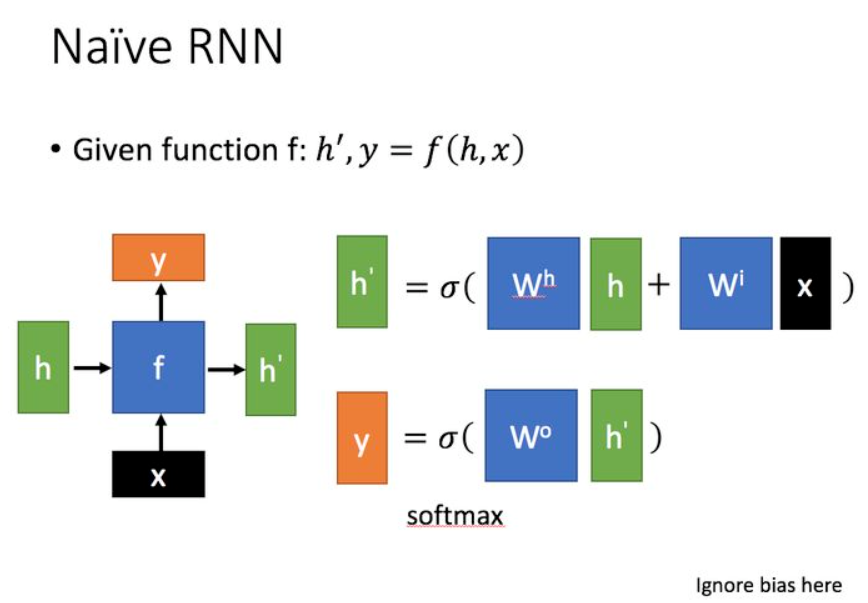
GRU模型 从RNN说起 循环神经网络 (Recurrent Neural Network,RNN)是一种用于处理序列数据的神经网络。相比一般的神经网络来说,他能够处理序列变化的数据。比如某个单词的意思会因为上文提到的内容不同而有不同的含义,RNN就能够很好地解决这类问题。
普通RNN
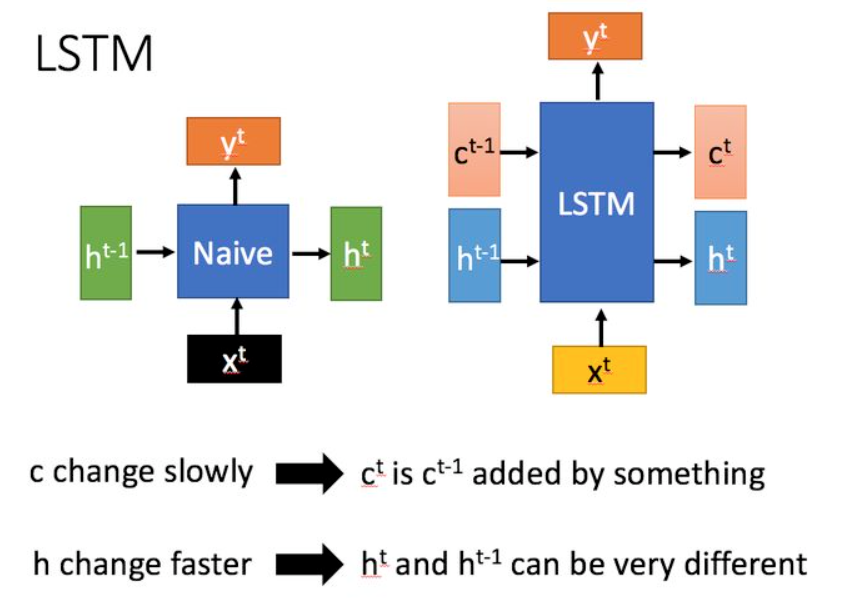
LSTM 长短期记忆 (Long short-term memory, LSTM)是一种特殊的RNN,主要是为了解决长序列训练过程中的梯度消失和梯度爆炸问题。简单来说,就是相比普通的RNN,LSTM能够在更长的序列中有更好的表现。
LSTM结构(图右)和普通RNN的主要输入输出区别如下所示。
GRU GRU(Gate Recurrent Unit)是循环神经网络 (Recurrent Neural Network, RNN)的一种。和LSTM(Long-Short Term Memory)一样,也是为了解决长期记忆和反向传播中的梯度等问题而提出来的。
GRU和LSTM在很多情况下实际表现上相差无几,那么为什么我们要使用新人GRU(2014年提出)而不是相对经受了更多考验的LSTM(1997提出)呢。
简单来说就是贫穷限制了我们的计算能力… ‘’
相比LSTM,使用GRU能够达到相当的效果,并且相比之下更容易进行训练,能够很大程度上提高训练效率,因此很多时候会更倾向于使用GRU。
基于Pytorch实现GRU模型 准备数据 这里需要注意,时间序列数据的准备,这里我们有15天的时间序列数据,一共三个特征(点赞、分享、评论),需要将原本(x,y)的张量给stack成(x, 15, y)的张量。具体处理的方法我就不说了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 dict_data = { 'trn_file_path' : './data/times_train_set2.npy' , 'test_file_path' : './data/times_val_set2.npy' , 'trn_label_path' : './data/times_trn_labels2.npy' , 'test_label_path' : './data/times_test_labels2.npy' , 'val_file_path' : '' , 'set_val_set' : False , } def prepared_data (dict_data ): train_set = pd.read_csv('./data/time_trn_data.csv' ) test_set = pd.read_csv('./data/time_test_data.csv' ) trn_x, trn_y = np.load(dict_data['trn_file_path' ], allow_pickle=True ), np.load(dict_data['trn_label_path' ], allow_pickle=True ) test_x, test_y = np.load(dict_data['test_file_path' ], allow_pickle=True ), np.load(dict_data['test_label_path' ], allow_pickle=True ) return train_set, test_set, (trn_x, trn_y), (test_x, test_y) gtrain_set, gtest_set, (gtrn_x, gtrn_y), (gtest_x, gtest_y) = prepared_data(dict_data) gru_dl_train_dataset = TensorDataset(torch.tensor(gtrn_x).float (), torch.tensor(gtrn_y).float ()) gru_dl_val_dataset = TensorDataset(torch.tensor(gtest_x).float (), torch.tensor(gtest_y).float ()) gru_dl_train = DataLoader(gru_dl_train_dataset, shuffle=True , batch_size=128 ) gru_dl_val = DataLoader(gru_dl_val_dataset, shuffle=True , batch_size=128 )
构建GRU模型 这里Pytorch很贴心的给出了相应的工具函数,因此我们用了很少的代码去实现了一个GRU模型:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 class GRU (nn.Module): def __init__ (self, INPUT_SIZE, hidden_units ): super (GRU, self).__init__() self.rnn = nn.GRU( input_size=INPUT_SIZE, hidden_size=hidden_units, num_layers=1 , batch_first=True ) self.out = nn.Linear(128 , 2 ) def forward (self, x ): r_out, h_state = self.rnn(x, None ) """ 因为是分类,这里我们只要最后一个预测结果 """ out = self.out(r_out[:,-1 ,:]) return out
初始化模型参数 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 BATCH_SIZE = 128 TIME_STEP = 15 INPUT_SIZE = 3 gru = GRU(INPUT_SIZE, 128 ) loss_func = nn.CrossEntropyLoss() optimizer = optim.Adam(params=gru.parameters(), lr=0.0001 ) metric_func = metric_func metric_name = 'acc'
模型训练 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 clear_output() EPOCH = 150 log_step_freq = 150 dfhistory = pd.DataFrame(columns=['epoch' , 'loss' , 'trn_' + metric_name]) print ('start_training.........' )nowtime = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S' ) print ('========' *8 + '%s' %nowtime)for epoch in range (1 , EPOCH+1 ): loss_sum = 0.0 metric_sum = 0.0 step = 1 for step, (gtrn_x, gtrn_y) in enumerate (gru_dl_train): step += 1 gtrn_x = gtrn_x.view(-1 , 15 , 3 ) predictions = gru(gtrn_x) predictions = predictions.squeeze(1 ) loss = loss_func(predictions, gtrn_y.to(torch.long)) try : metric = metric_func("acc" , F.softmax(predictions), gtrn_y) except ValueError: pass optimizer.zero_grad() loss.backward() optimizer.step() loss_sum += loss.detach().numpy() metric_sum += metric.item() if step % log_step_freq == 0 : print (("[step=%d] loss: %.3f, " + metric_name + ": %.3f" ) % (step, loss_sum/step, metric_sum/step)); info = (epoch, loss_sum/step, metric_sum/step) dfhistory.loc[epoch-1 ] = info print (("\nEPOCH=%d, loss=%.3f, " + metric_name + " = %.3f" ) %info) nowtime = datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S" ) print ('\n' + '==========' * 8 + '%s' %nowtime) print ('Finished Training' )
基于Pytorch Concatenate NFM和GRU模型 这里对两个模型进行Concatenate是为了获取时间序列信息和文本信息的结合,以便更好的预测结果。我这里偷了一个懒,直接拿模型的输出作为Concatenate 模型的输入,构建了单层神经网络来输出最终的结果。实际要做的更科学点,应该将两个模型输出层前一层提取到的特征网络进行concatenate,这样才算是真正意义上的结合了文本信息和时间序列信息,然后再进行预测。
构建Concatenate模型 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 class ConcatenateModel (nn.Module): """ n_feature: 4 对应nfm、gru的输出拼接后的特征数 n_hidden: 64 """ def __init__ (self, nfm, gru, n_feature, n_hidden, n_output, dropout=0. ): super (ConcatenateModel, self).__init__() self.nfm = nfm self.gru = gru self.hidden = nn.Linear(n_feature, n_hidden) self.predict = nn.Linear(n_hidden, n_output) self.dropout = nn.Dropout(dropout) def forward (self, x_content, x_times ): x1, x2 = self.nfm(x_content), self.gru(x_times) x = torch.cat((x1, x2), 1 ) x = self.hidden(x) x = self.dropout(x) x = self.predict(x) out = F.sigmoid(x) return out
导入数据 1 2 3 4 5 6 7 concat_train_dataset = TensorDataset(torch.tensor(trn_x).float (), torch.tensor(gtrn_x).float (), torch.tensor(trn_y).float ()) concat_val_dataset = TensorDataset(torch.tensor(test_x).float (), torch.tensor(gtest_x).float (), torch.tensor(test_y).float ()) concat_train = DataLoader(concat_train_dataset, shuffle=True , batch_size=128 ) concat_val = DataLoader(concat_val_dataset, shuffle=True , batch_size=128 )
设置模型参数 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 def metric_func (m_type, y_pred, y_true ): if m_type == "auc" : pred = y_pred.data y = y_true.data return roc_auc_score(y, pred) if m_type == "acc" : y_pred = torch.where(y_pred>0.5 , torch.ones_like(y_pred), torch.zeros_like(y_pred)).numpy() y = y_true.numpy() return precision_score(y, y_pred, average='micro' ) if m_type == "f1-score" : y_pred = y_pred.argmax(dim=1 ).numpy() y = y_true.numpy() return f1_score(y, y_pred, average='micro' ) INPUT_SIZE = 4 HIDDEN_UNITS = 128 OUTPUT_SIZE = 1 DROPOUT = 0.7 nfm = torch.load('./NFM3.pkl' ) gru = torch.load('./GRU.pkl' ) cm = ConcatenateModel(nfm, gru, INPUT_SIZE, HIDDEN_UNITS, OUTPUT_SIZE, DROPOUT) loss_func = nn.BCELoss() optimizer = optim.Adam(params=cm.parameters(), lr=0.00001 ) metric_func = metric_func metric_name = 'acc'
训练模型 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 clear_output() EPOCH = 150 log_step_freq = 150 dfhistory = pd.DataFrame(columns=['epoch' , 'loss' , 'trn_' + metric_name]) print ('start_training.........' )nowtime = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S' ) print ('========' *8 + '%s' %nowtime)for epoch in range (1 , EPOCH+1 ): loss_sum = 0.0 metric_sum = 0.0 step = 1 for step, (content_features, times_features, labels) in enumerate (concat_train): step += 1 predictions = cm(content_features, times_features) predictions = predictions.squeeze(1 ) loss = loss_func(predictions, labels) try : metric = metric_func("acc" , predictions, labels) except ValueError: pass optimizer.zero_grad() loss.backward() optimizer.step() loss_sum += loss.detach().numpy() metric_sum += metric.item() if step % log_step_freq == 0 : print (("[step=%d] loss: %.3f, " + metric_name + ": %.3f" ) % (step, loss_sum/step, metric_sum/step)); info = (epoch, loss_sum/step, metric_sum/step) dfhistory.loc[epoch-1 ] = info print (("\nEPOCH=%d, loss=%.3f, " + metric_name + " = %.3f" ) %info) nowtime = datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S" ) print ('\n' + '==========' * 8 + '%s' %nowtime) print ('Finished Training' )
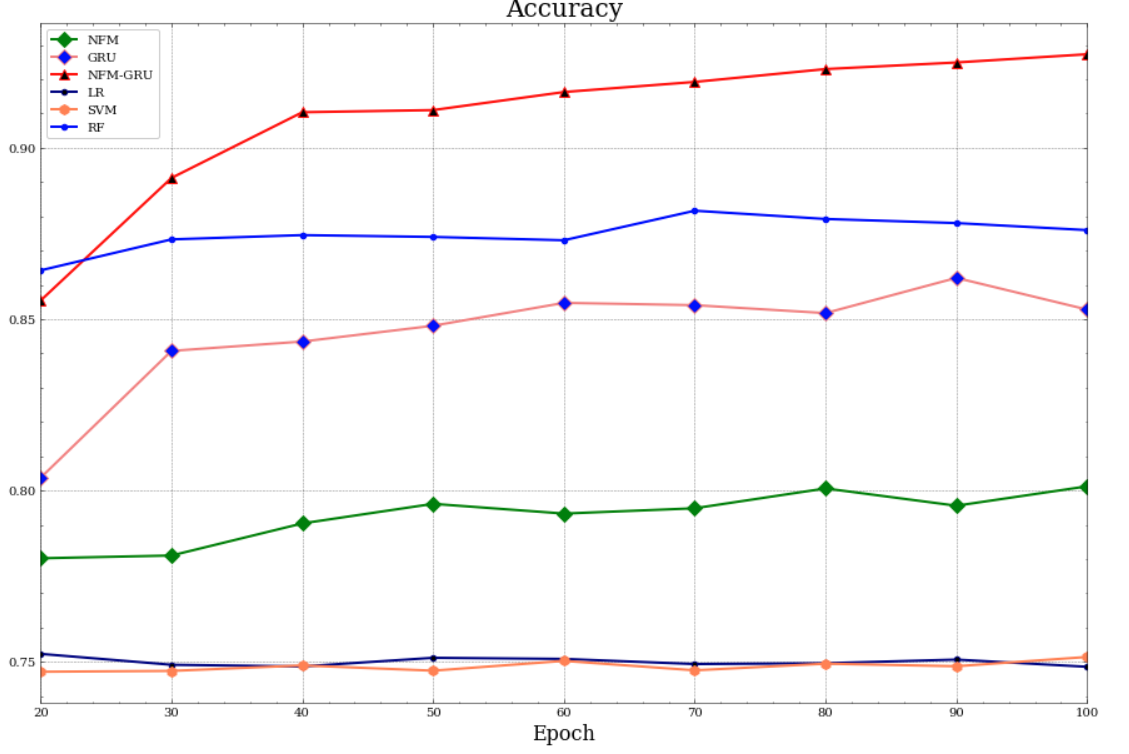
总结 最后还构建几个基线模型进行对比训练,可以看出效果还是不错的。