引入
最近有点空闲,继续开始折腾博客,先前五月份的时候对博客主题进了更新升级,后面因为其他事项,先前博客的一些魔改一直没有应用到主题升级后的博客以及一些魔改应用后存在一些问题,后面会在这个专栏逐个进行记录。
首先呢,是Akilar大佬提供的Categories Magnet(分类磁贴)插件,参考文章。我这里魔改使用的是大佬的插件版,应用后发现该插件将所有分类,包括二级分类(一共41个类)都给磁贴展示了出来,而我实际是想要展示12个大类别即可。我向Akilar大佬咨询了这个问题,大佬也是很nice,及时回复了我的咨询,并给出了方案—“卸载插件。换用下方折叠的4.0版本源码魔改。这个调用主题自带的函数,深度只设置了一级,刚好只加载一级分类。”
但是呢,我看大佬提供的4.0版本源码魔改的配置太冗余,远没有插件版的配置好用,对此,我只好埋头苦肝大佬的插件源码,企图在插件源码上解决这个问题,所幸最终是解决了,下面记录下我的整个分析修改的过程以及存在的一些疑问点。
补充
这里根据大佬文章的评论补充点内容~
Hexo官方文档-分类和标签
Hexo 不支持指定多个同级分类。下面的指定方法:
1
2
3
| categories:
- Diary
- Life
|
会使分类Life成为Diary的子分类,而不是并列分类。因此,有必要为您的文章选择尽可能准确的分类。
如果你需要为文章添加多个分类,可以尝试以下 list 中的方法:
1
2
3
4
| categories:
- [Diary, PlayStation]
- [Diary, Games]
- [Life]
|
此时这篇文章同时包括三个分类: PlayStation 和 Games 分别都是父分类 Diary 的子分类,同时 Life 是一个没有子分类的分类。
上面补充的内容,大家自行验证,我这边并没有验证,只是做一个记录!
分析过程
首先,我不想采用冗余的解决方案,只想在现有的插件里去修改大佬写好的代码逻辑来实现我想要的只展示一级分类目录磁贴的效果,因此,需要先下载大佬提供的插件,进入博客根目录下载:
1
2
3
| pwsh CPU: 66% | MEM: 22/34GB 2ms
╭─ ♥ 10:53 | D: hexo-admin
╰─ npm install hexo-butterfly-categories-card --save
|
接着,进入根目录里的node_modules文件夹,里面存放了你下载好要使用的插件,找到大佬的插件目录进入:
1
2
3
4
5
6
7
8
9
10
11
12
13
| pwsh CPU: 67% | MEM: 22/34GB 3ms
╭─ ♥ 10:54 | D: hexo-admin
╰─ cd .\node_modules\
pwsh CPU: 67% | MEM: 23/34GB 1ms
╭─ ♥ 10:55 | D: node_modules
╰─ ls | findstr "categories"
hexo-butterfly-categories-card
pwsh CPU: 67% | MEM: 23/34GB 1ms
╭─ ♥ 10:56 | D: node_modules
╰─ code .\hexo-butterfly-categories-card\
|
在用IDE打开该文件夹后,直接看到index.js文件 :
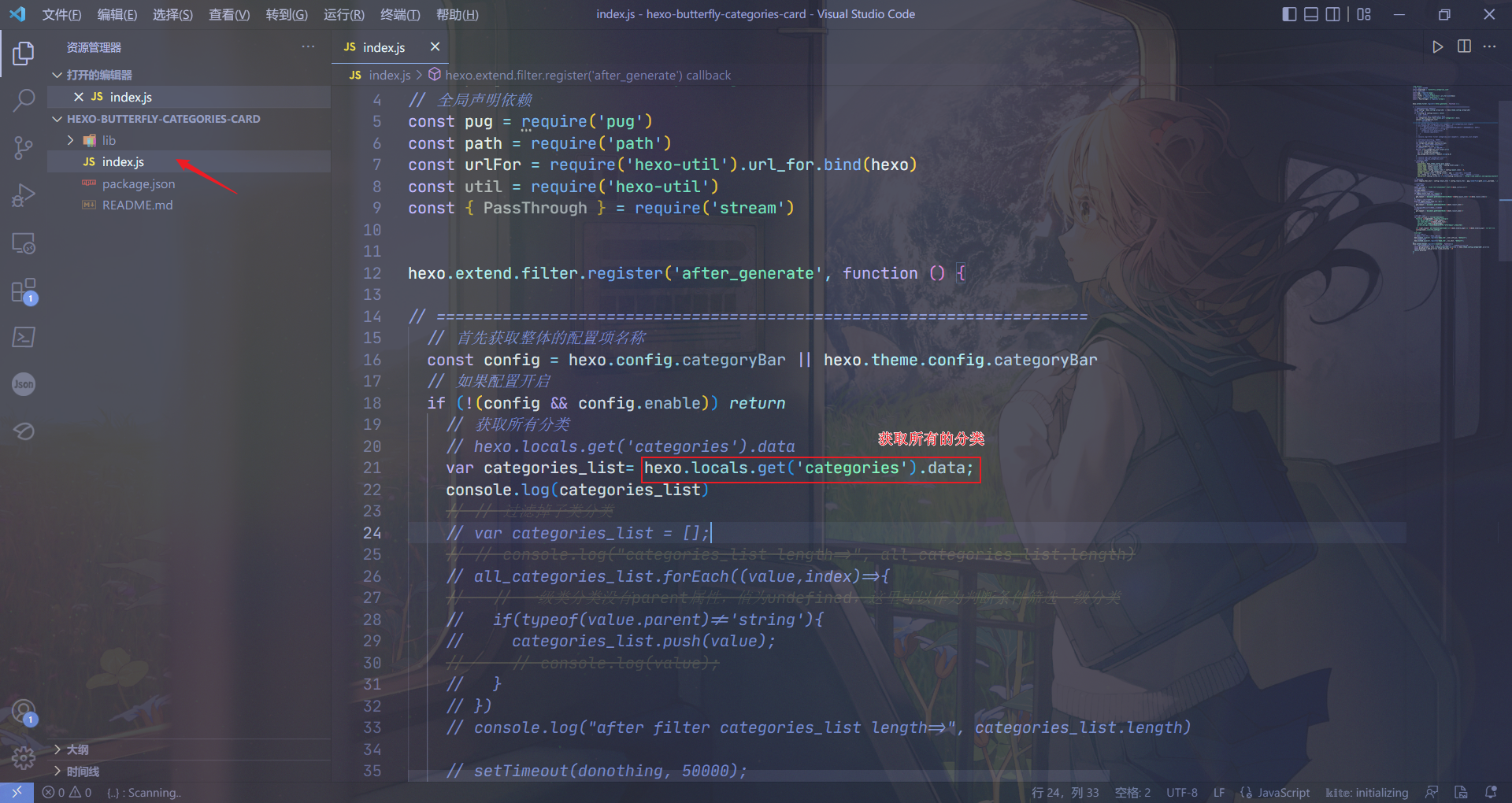
在里面可以看到这样一行代码=>hexo.locals.get('categories').data,我们查找官方文档:
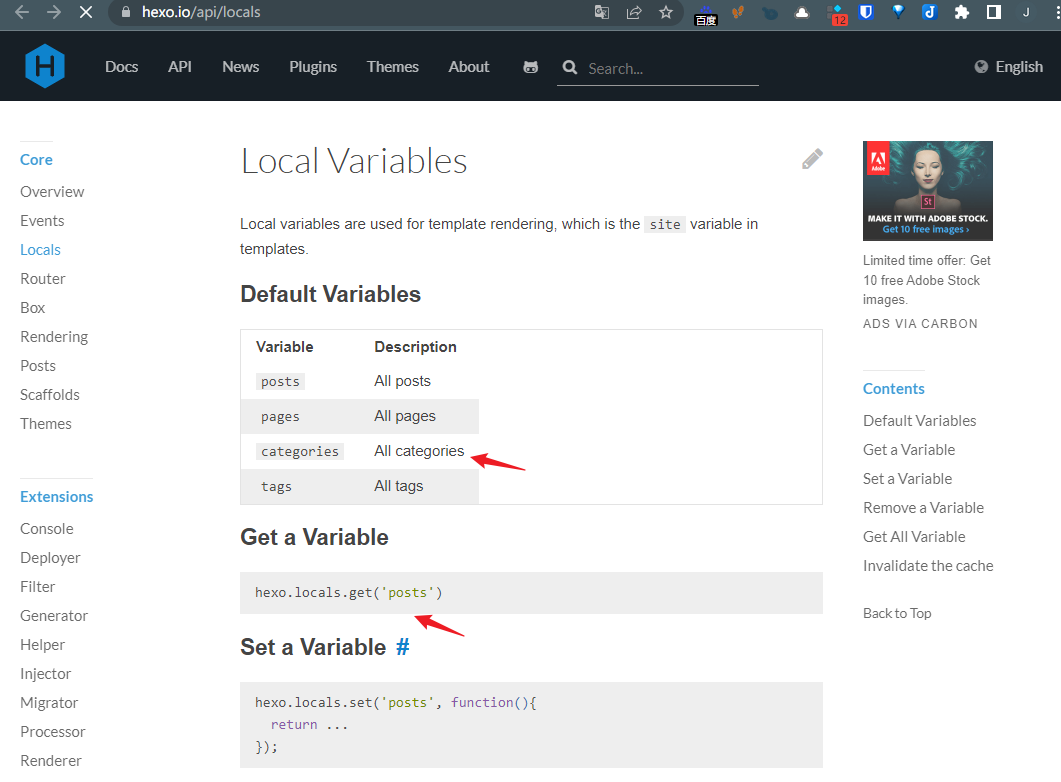
可以知道,该代码获取所有的分类,并不仅仅是一级分类。对此,我们只需要console.log(categories_list)查看该变量里的所有分类数据中,一级分类和多级分类数据之间的区别,再根据这个区别去过滤掉多级分类数据对象即可实现只展示一级分类磁贴了。
对此,我们先修改代码:
1
2
3
4
5
6
| if (!(config && config.enable)) return
var categories_list= hexo.locals.get('categories').data;
console.log(categories_list)
|
并在本地启动博客,查看输出:
1
| hexo cl && hexo g && gulp && hexo s
|
接下来,查看输出(这里由于数据过多,我们找一个举例):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| [
_Document {
name: '容器技术',
_id: 'cl6k4eirc0004m8vz9n65gqpz',
slug: [Getter],
path: [Getter],
permalink: [Getter],
posts: [Getter],
length: [Getter]
},
_Document {
name: 'Docker',
parent: 'cl6k4eirc0004m8vz9n65gqpz',
_id: 'cl6k4eirq000rm8vzeq7d758j',
slug: [Getter],
path: [Getter],
permalink: [Getter],
posts: [Getter],
length: [Getter]
},
...
]
|
可以看到,一级分类数据对象-容器技术及其子类数据对象-Docker都被打印出来了。对比可以发现,子类对象存在parent属性,而一级分类数据对象并不存在parent属性。对此,我们只需要根据parent属性去过滤数据,即可实现磁铁只展示一级分类对象数据了,到此大功即将告成!
问题解决方案
通过上面分析的过程,我们知道,只需要将一级分类数据参照parent属性过滤即可。
解决方案
此方案是在var categories_list= hexo.locals.get('categories').data;代码执行后,新建一个变量,赋值空数组给此变量。接着对categories_list进行过滤,将一级分类筛选出来,添加到空数组变量中,然后用这个变量代替categories_list执行后续的逻辑。代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| if (!(config && config.enable)) return
// 获取所有分类
// hexo.locals.get('categories').data
- var categories_list= hexo.locals.get('categories').data;
+ var all_categories_list= hexo.locals.get('categories').data;
// 过滤掉子类分类
+ var categories_list = [];
+ all_categories_list.forEach((value,index)=>{
+ // 一级类分类没有parent属性,值为undefined,这里可以作为判断条件筛选一级分类
+ if(typeof(value.parent)!='string'){
+ // 将一级分类数据对象添加到空数组对象categories_list里
+ categories_list.push(value);
+ // console.log(value);
+ }
+ })
|
经测试后,代码正常执行,分类磁贴成功展示了一级分类目录,可喜可贺!
优化
到此,已经实现了磁贴只展现一级分类,但在实际使用的时候发现一级分类的展示顺序并不是确定的,这就导致很难确定一个分类的位置,难以给分类添加描述信息。因此,这里进行优化,对每次筛选后的数据对象进行一次排序,代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
| // 过滤掉子类分类
var categories_list = [];
// console.log("categories_list length=>", all_categories_list.length)
all_categories_list.forEach((value,index)=>{
// 一级类分类没有parent属性,值为undefined,这里可以作为判断条件筛选一级分类
if(typeof(value.parent)!='string'){
categories_list.push(value);
// console.log(value._id);
}
})
+ // 对筛选出来后的数组进行排序
+ //by函数接受一个成员名字符串做为参数
+ //并返回一个可以用来对包含该成员的对象数组进行排序的比较函数
+ var by = function(name){
+ return function(o, p){
+ var a, b;
+ if (typeof o === "object" && typeof p === "object" && o && p) {
+ a = o[name];
+ b = p[name];
+ if (a === b) {
+ return 0;
+ }
+ if (typeof a === typeof b) {
+ return a < b ? -1 : 1;
+ }
+ return typeof a < typeof b ? -1 : 1;
+ }
+ else {
+ throw ("error");
+ }
+ }
+ };
+ categories_list.sort(by("name"))
|
这里要注意选择的对象里的排序参考属性,我之前选择_id作为数据对象排序的属性后,每次排序的结果都不一致,因此可以推断这个_id并不是固定的,而是随机生成的。相对于随机生成的_id,每个一级分类的name属性则是确定的,所以这里将name属性作为排序参考属性后,排序结果保持了一致性。最终实现了结果稳定性的优化。
参考



